1. Feature Store Components
MP
Minh Pham / April 03, 2024
2 min read
Key Components
Five key components of a Feature Store
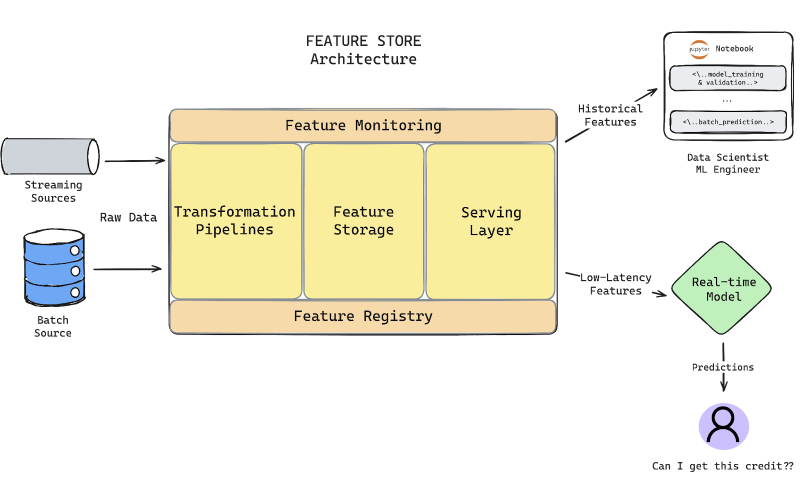
1. Feature Engineering (Transformations)#
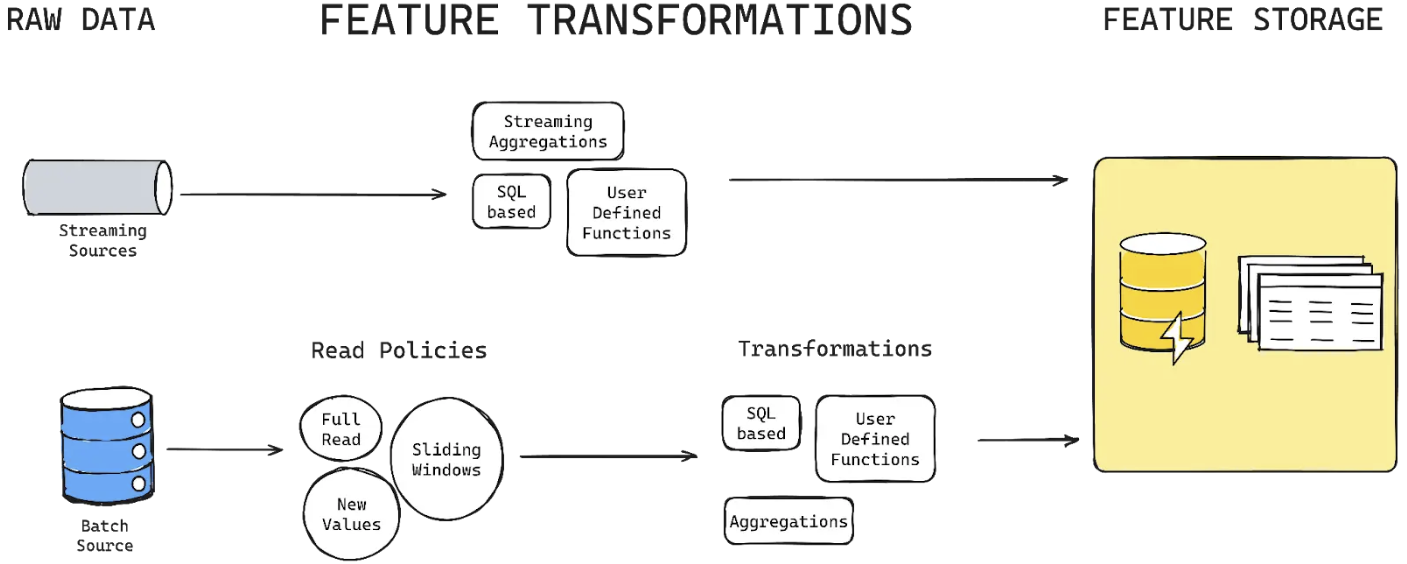
- Feature engineering phase should offers multiple transformation techniques like select, filter, aggregate, and manipulate raw data into reusable features for ML models
- Different data sources present unique challenges:
- Streaming sources: Dealing with continuous data ingestion and processing
- Batch sources: Dealing with a large amount of static data, ingestion happens regularly or on-demand
- Variety in data formats: CSV files, S3 bucket, Parquet files…
2. Feature Storage#
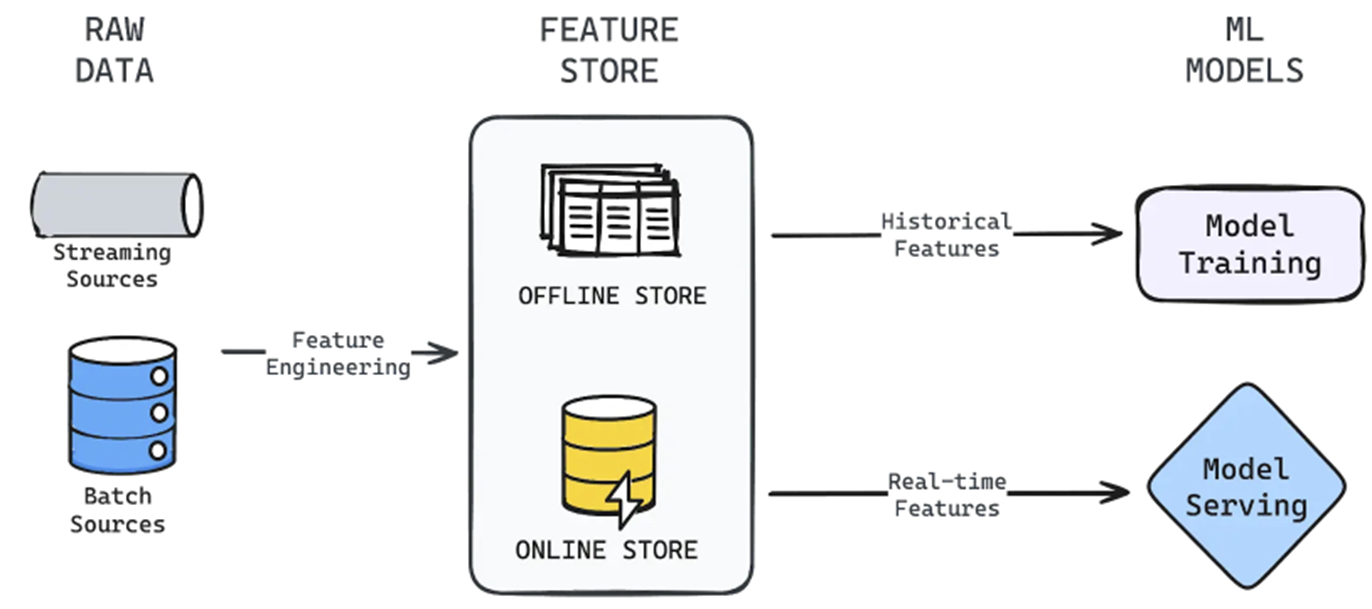
- The feature storage layer can be seen as a dual-database system. On one side, it stores historical data with a focus on columnar retrieval. On the other, it features a row-oriented retrieval system focusing on low-latency data lookup.
- The offline store is the backbone for training and batch predictions. It is often time-based and is appended to rather than rewritten. Must be cost-efficient for storing large amounts of data.
- The online store stores only the latest feature vectors for a specific feature set entity. It is engineered for speed and responsiveness. Needed in real-time cases like: Fraud detection systems or real-time personalization in digital platforms.
3. Feature Registry#
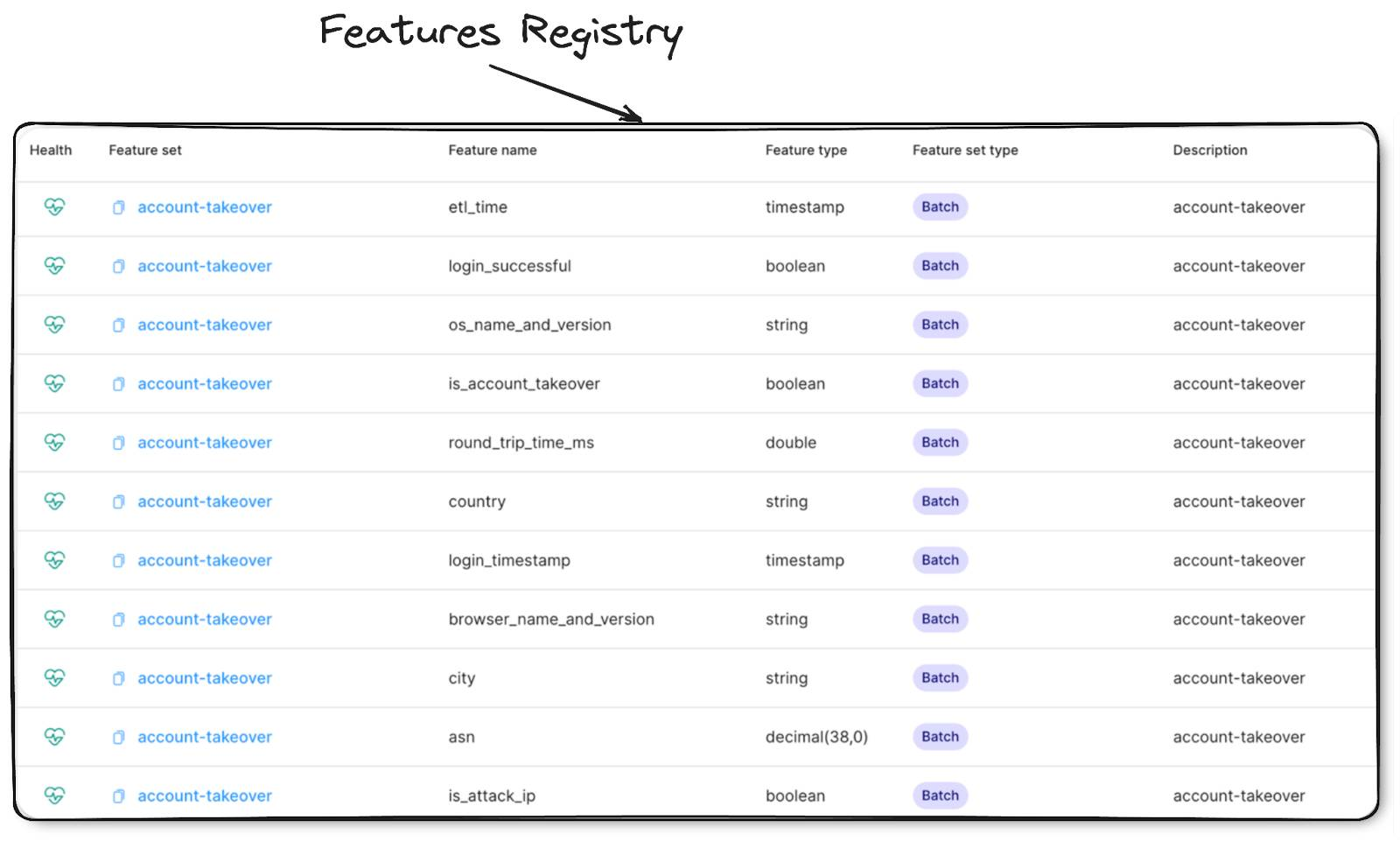
- This can be seen as Centralized repository for all features within the feature store
- Stores metadata of feature (set, type, definition…)
- Feature registry must also manage access control (privilege to access to a set of features and type of access granted)
4. Feature Serving#
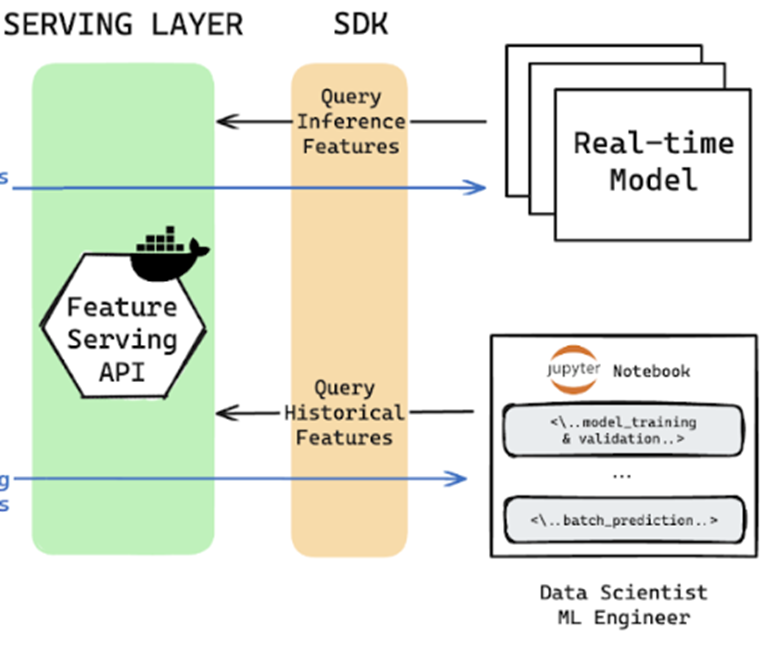
- Enables DS/AI engineers and Real-time Models to interact with Feature Storage, retrieving historical features for training or fetching the latest feature vector for a specific entity
- The feature serving client relies on an API or SDK to perform a specific action (like fetching features)
5. Feature Monitoring#
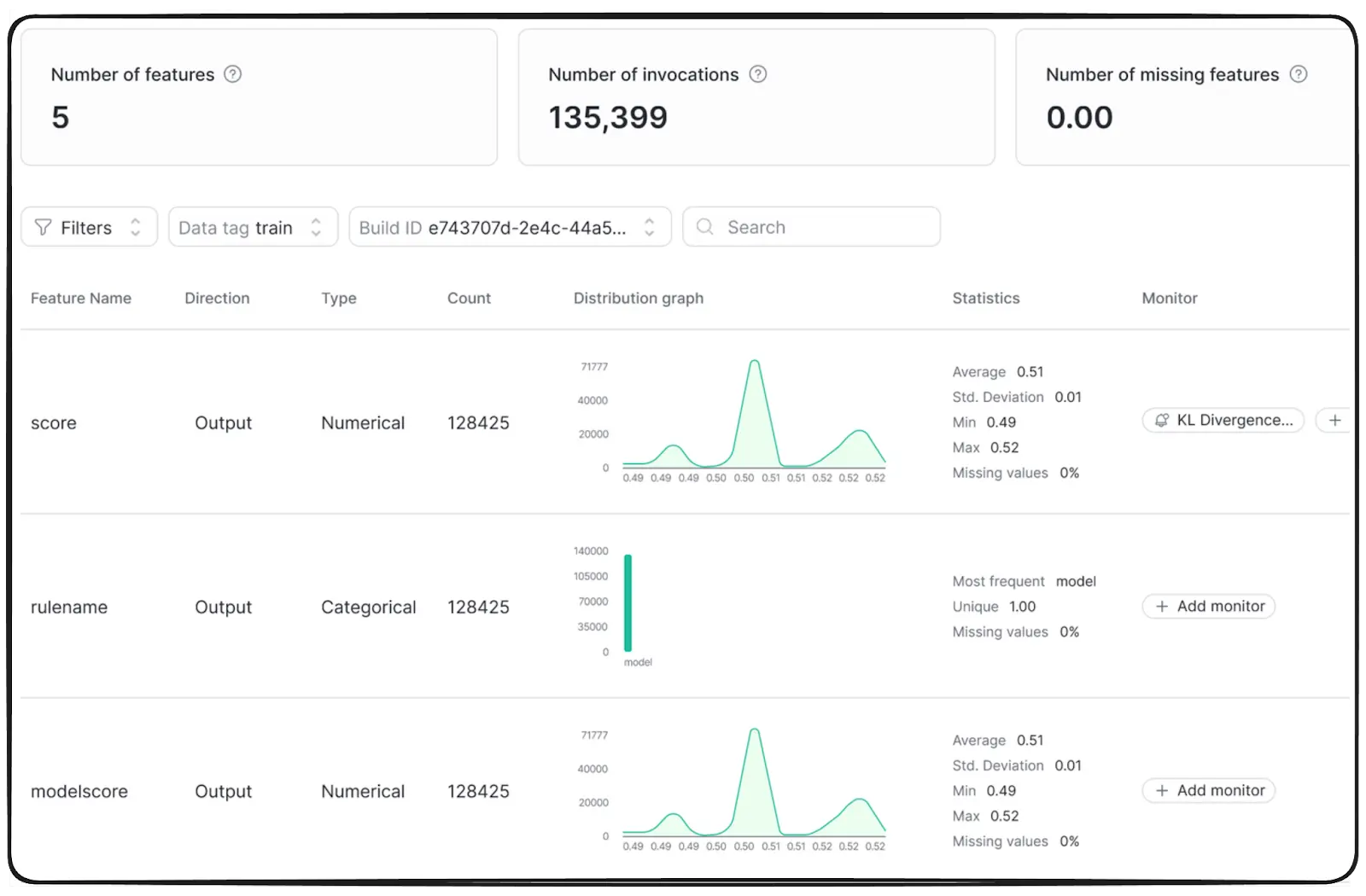
This is a step to ensure ongoing quality, help detecting changes in the features data, cover the following aspects:
- Data quality: ensuring data anomalies stay within defined error limits
- Data drift: The statistical distribution of data over time
- Serving performance: Throughput, serving latency, and requests per second
- Training-Serving Skew: The consistency between the conditions during model training and real-time serving.