0. MLOps Overview
Minh Pham / April 01, 2024
4 min read
MLOps Overview
Overview of MLOps - the vital intersection of machine learning and operations, and how it can ensures efficient ML development and robust deployments.
This document is mainly adapted from Qwak materials.
Concept and Definition (What)#
MLOps (Machine Learning Operations) is a paradigm, including aspects like best practices, sets of concepts, as well as a development culture when it comes to the end-to-end conceptualization, implementation, monitoring, deployment, and scalability of machine learning products.
Most of all, it is an engineering practice that leverages three contributing disciplines: machine learning, software engineering (especially DevOps), and data engineering
MLOps is aimed at productionizing machine learning systems by bridging the gap between development (Dev) and operations (Ops)
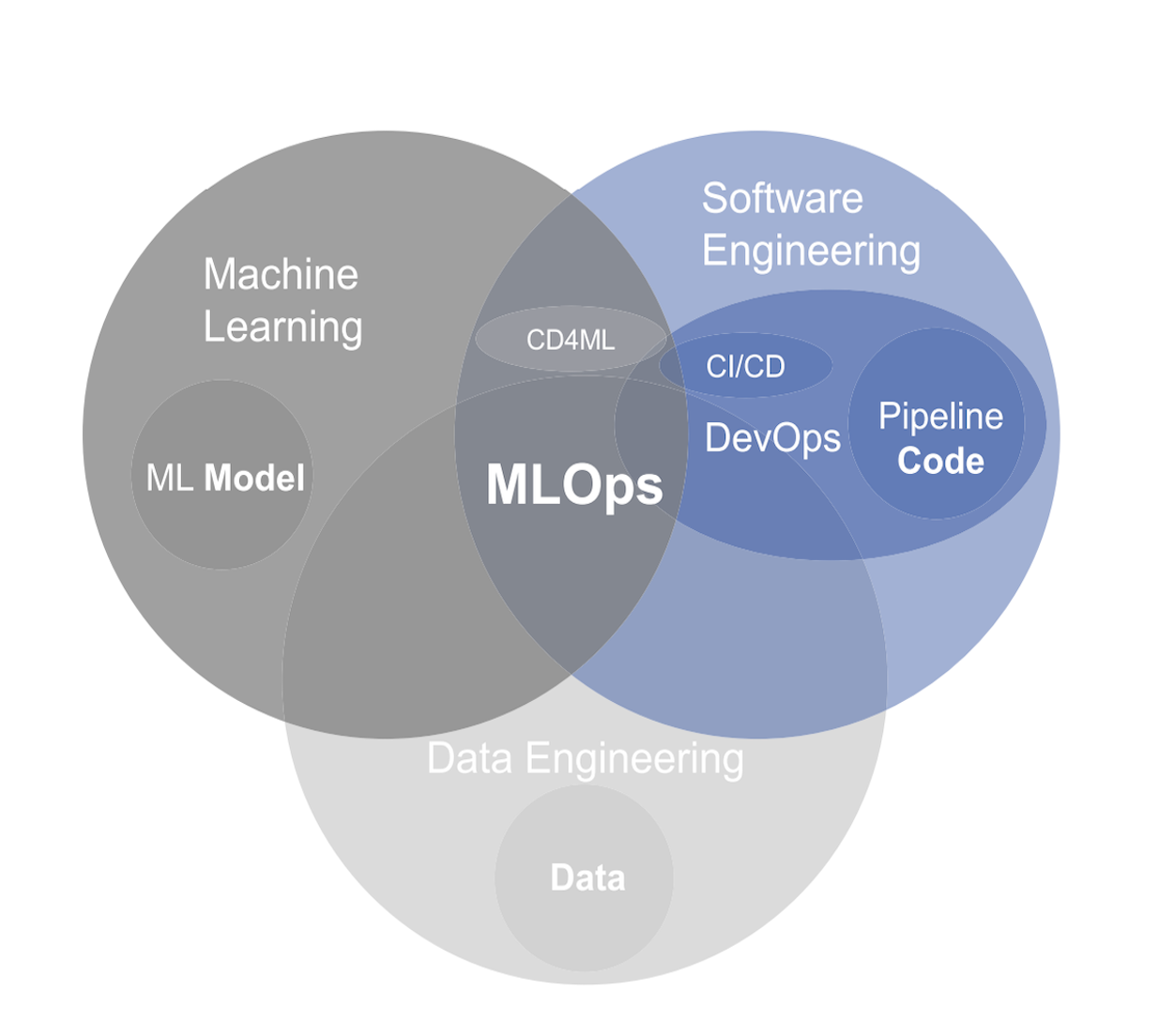 | 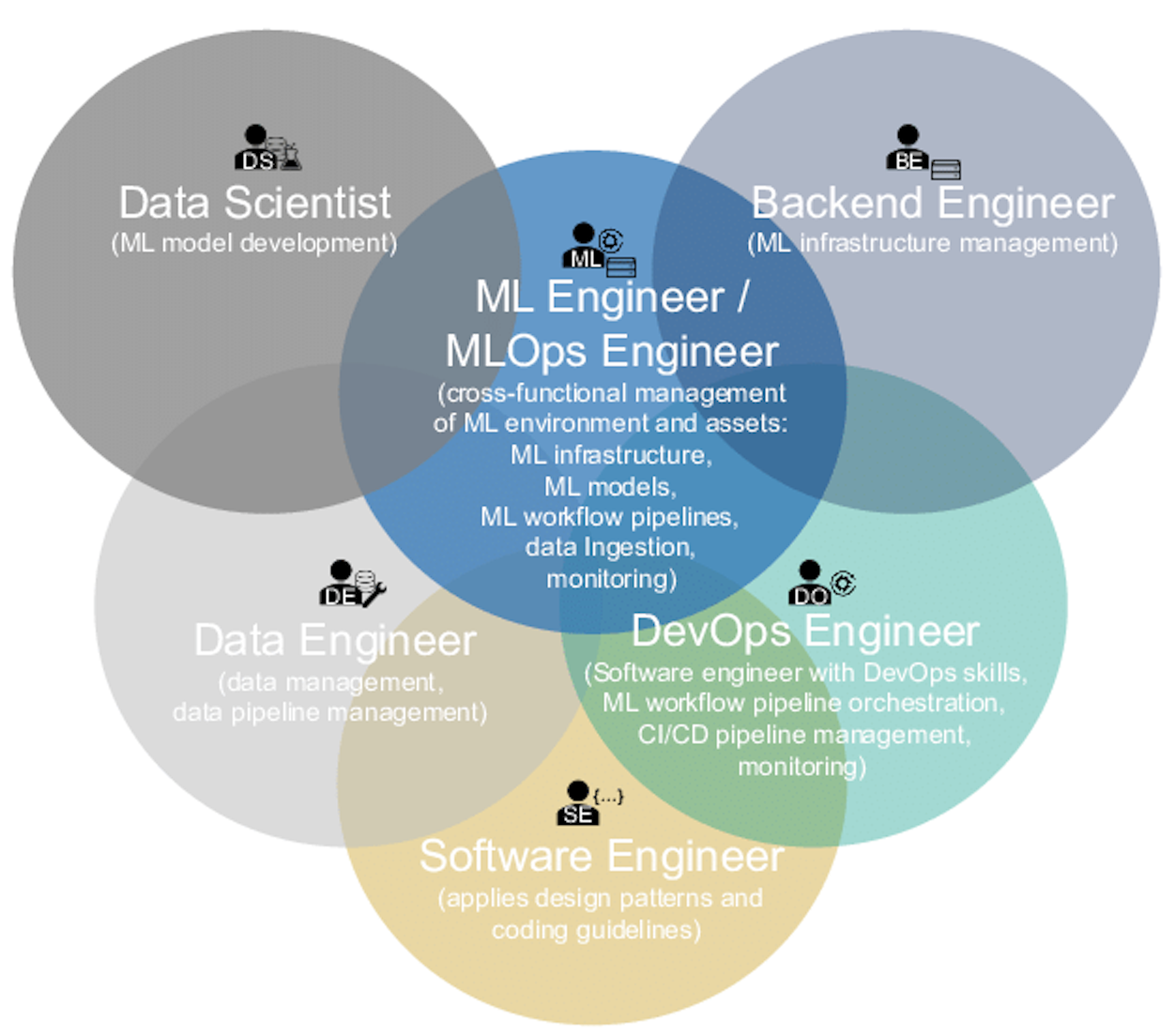 |
Why MLOps?#
Dynamic vs Static: Unlike experimental ML, which often uses fixed datasets, production environments are dynamic. They require systems that can adapt to fluctuating user demand and data variability.
Inelastic Demand: User requests in production can come at any time, requiring a system that can auto-scale to meet this inelastic demand.
Data Drift: Production systems need constant monitoring for changes in data distribution, known as data drift, which can affect model performance.
Real-Time Needs: Many production applications require real-time predictions, necessitating low-latency data processing.
The Traditional Machine Learning Setup#
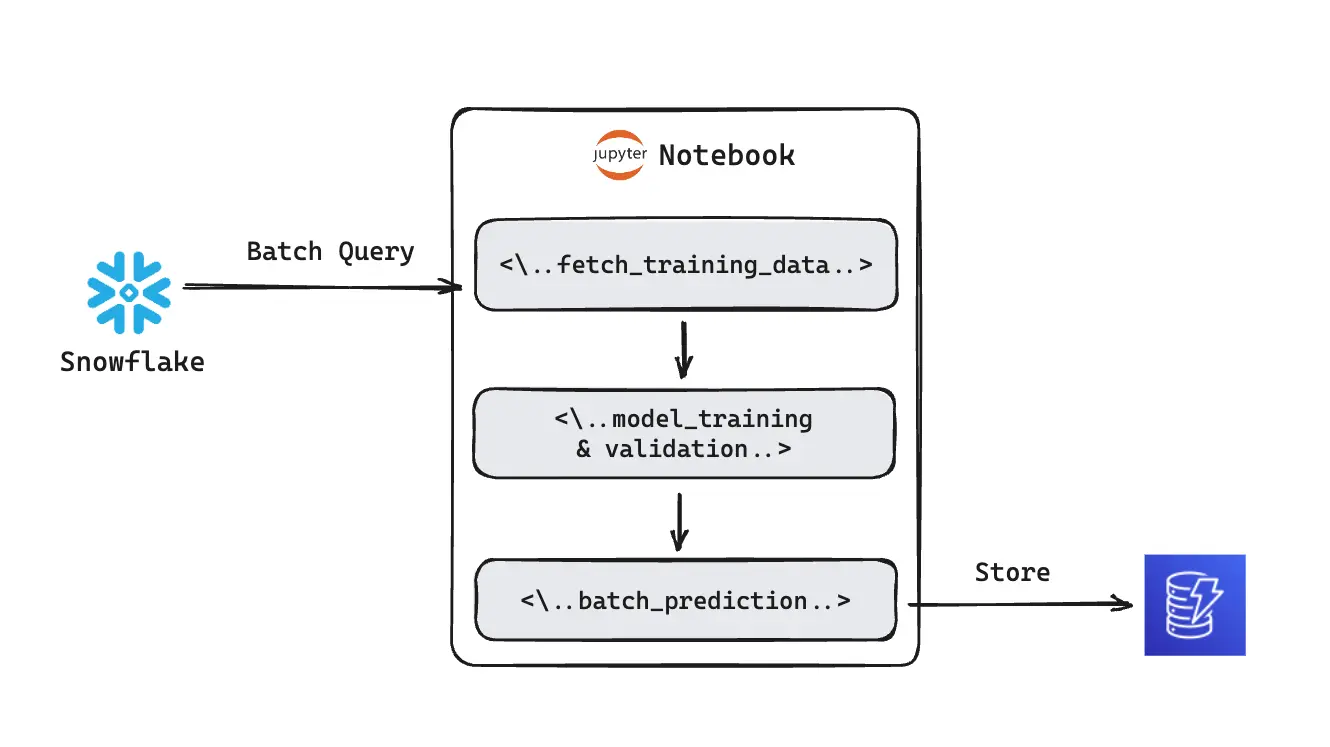
- Data preprocessing and feature engineering are typically done ad-hoc using tools like Jupyter notebooks. There's usually no version control for the data transformations or features, making it difficult to reproduce results.
- The model is trained and validated using the same Jupyter notebook environment. Hyperparameters are often tuned manually, and the training process lacks systematic tracking of model versions, performance metrics, or experiment metadata.
- The prediction results and any model artifacts are manually saved to a data storage service, such as a cloud-based data store. There's usually no versioning or tracking, making managing model updates or rollbacks challenging.
From Notebooks to Production: An Integrated ML System#
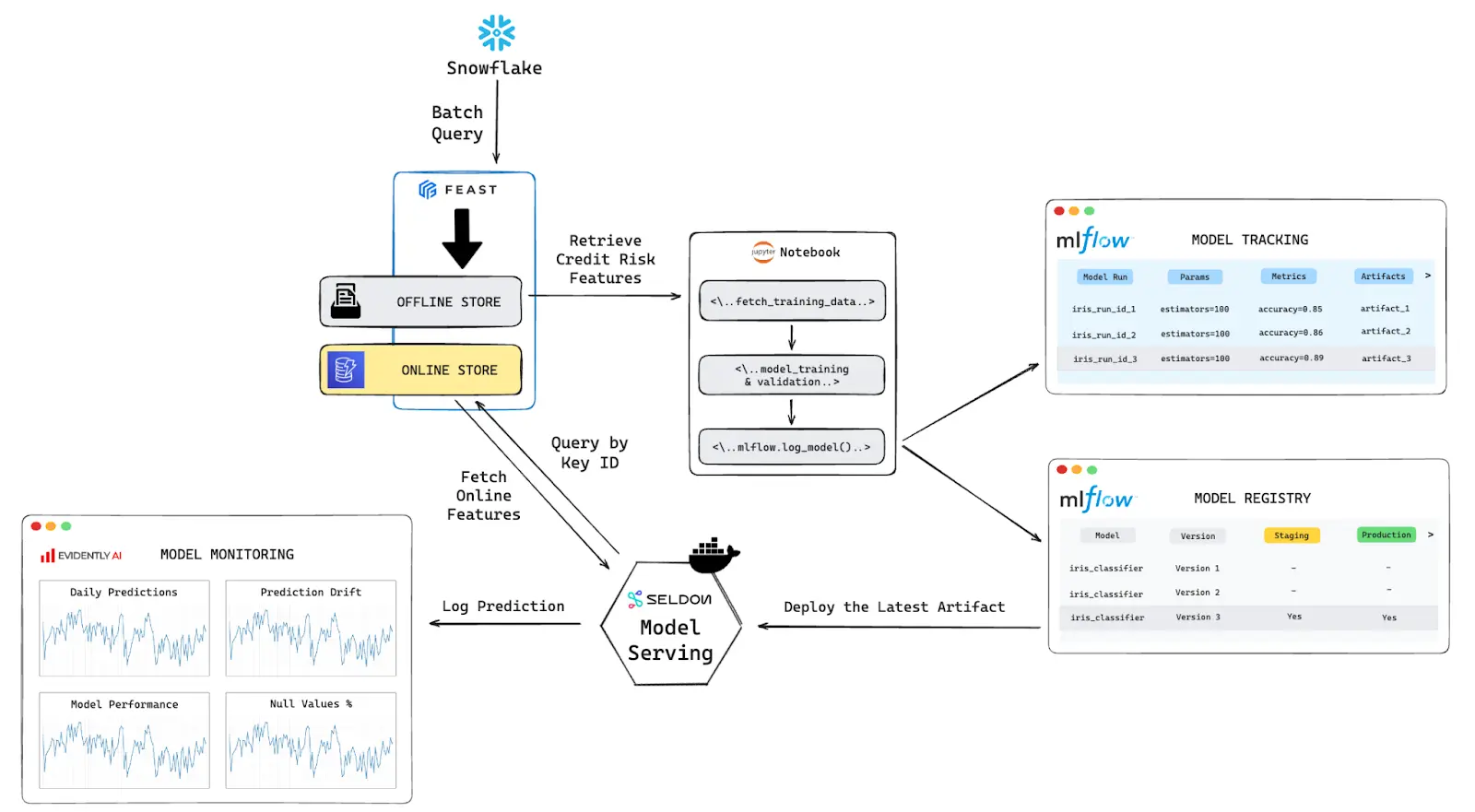
Core Components: (WIP - Will update link to each component later)
- Feature Store: a centralized repository that acts as a bridge between raw data and machine learning models. It streamlines the feature engineering process and ensures consistency across different models. Feature stores can be broadly categorized into two types:
- Offline Store: batch processing of features, use for model training
- Online Store: serves features in real-time for model inference, quickly retrieves the relevant features to be fed into the model when a request come in.
- Model Tracking and Versioning: Capture parameters, metrics, and artifacts during the model training process. For model registry, it will help managing different iterations of trained models and according working environment.
- Model Deployment and Serving: While batch predictions are often executed offline where latency is less critical, real-time predictions demand low-latency responses to HTTP requests. Without deployment, an ML model remains just a theoretical construct; it's the deployment that brings it to life in a real-world context.
- Model Monitoring: Ensure that the model's performance remains consistent and reliable over time (avoid model drift) when interacting with dynamic and constantly changing data
- Workflow Orchestration: Orchestrating the various moving parts of an ML system is no small feat. From data ingestion to model deployment, each step is a cog in a complex machinery. Doing this manually is not just tedious but prone to errors.
A complete workflow with Kubernetes deployment can be illustrated as below:
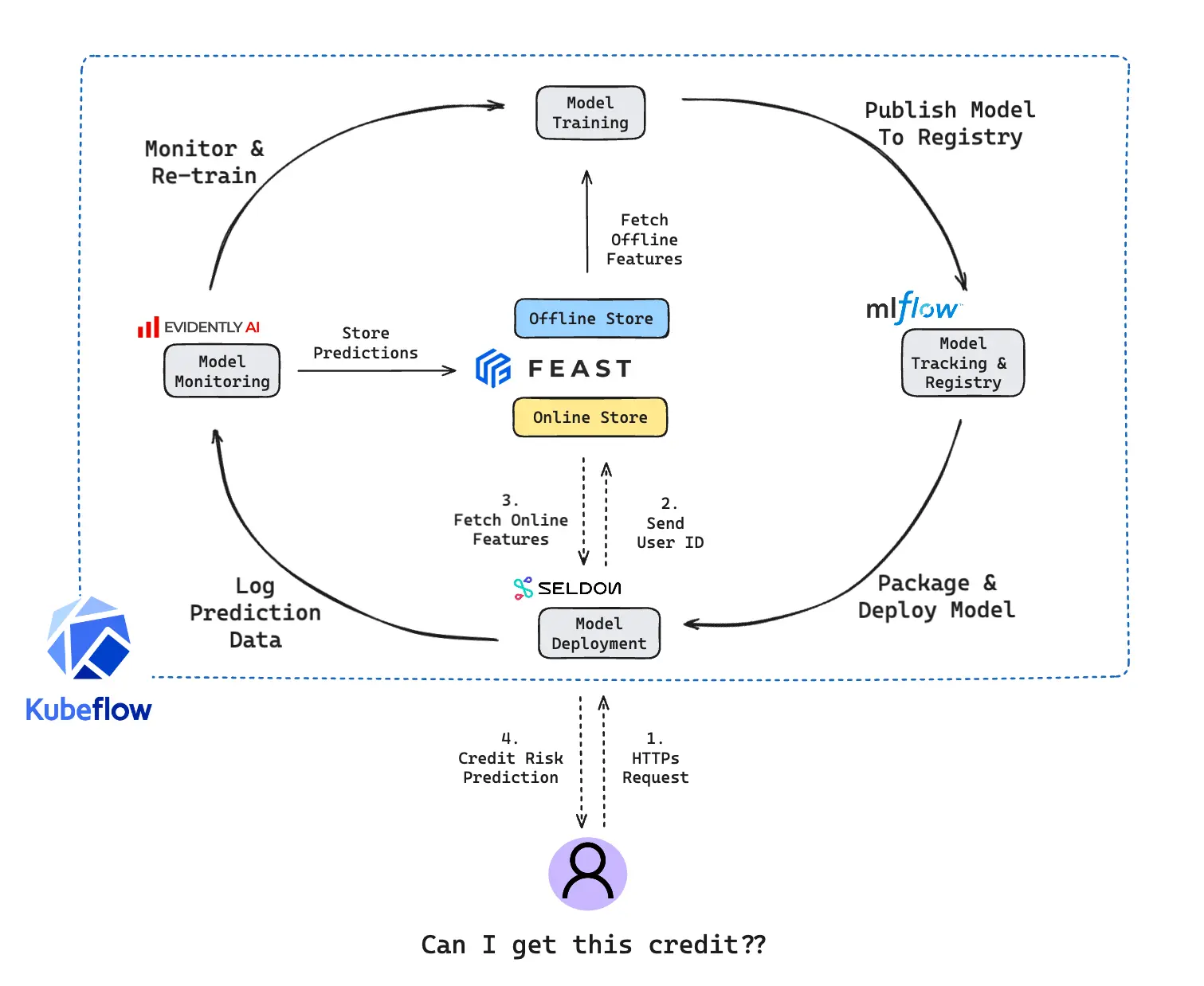
Here is the summarized workflow and related open-source tools to build a full MLOps pipeline
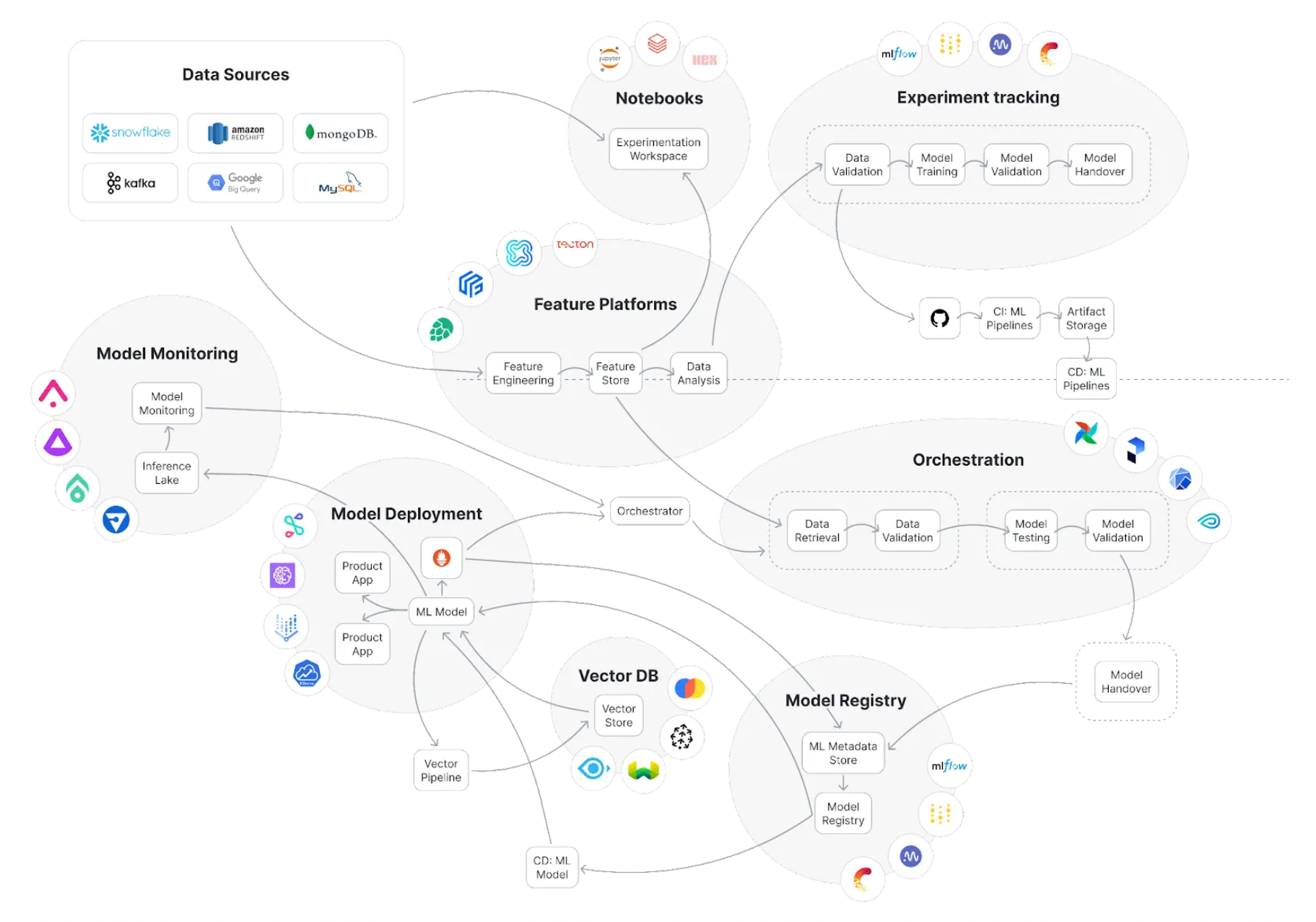
References#
Research Article: Machine Learning Operations (MLOps): Overview, Definition, and Architecture
Qwak MLOps: